Especialistas da Sociaro prepararam a tradução de outro artigo que ajudará você a entender o que é Aprendizado de Máquina.
O artigo de Megan Dibble do Medium Towards Data Science é a explicação mais simples de como os modelos de ML funcionam.
Se você é novo em ciência de dados, o título não foi destinado a ofendê-lo. Este é o meu segundo post sobre uma pergunta de entrevista popular que diz algo como: "explique para mim [inserir assunto técnico], como você explicaria para uma criança de cinco anos".
Acontece que alcançar o nível de entendimento de uma criança de cinco anos é bastante difícil. Então, enquanto este artigo pode não ser totalmente claro para um pré-escolar, será claro para alguém que tem pouca ou nenhuma experiência em ciência de dados (e se você achar que não é o caso, por favor escreva sobre isso nos comentários).
Vou começar explicando o conceito de aprendizado de máquina, bem como seus diferentes tipos e depois passar para a explicação de modelos simples. Não entrarei muito na matemática, mas estou pensando em fazê-lo em meus artigos futuros. Aproveite!
Definição de Aprendizado de Máquina
O aprendizado de máquina ocorre quando você carrega uma grande quantidade de dados em um programa de computador e escolhe um modelo que "se ajustará" a esses dados para que o computador (sem sua ajuda) possa fazer previsões. O computador constrói modelos usando algoritmos que variam de equações simples (como a equação de uma linha reta) a sistemas muito complexos de lógica / matemática que permitem ao computador fazer as melhores previsões possíveis.
O nome aprendizado de máquina é apropriado porque, uma vez que você escolhe um modelo para usar e ajustar (em outras palavras, melhorar com ajustes), a máquina usará o modelo para aprender padrões em seus dados. Então você pode adicionar novas condições (observações) e ele preverá o resultado!
Quem usa nossos serviços

Descubra a emoção de girar os rolos no Fortune Tiger, onde cada jogada pode trazer grandes vitórias e diversão sem fim.

Isso significa que você terá uma boa experiência jogando no celular em qualquer um dos melhores cassino online listados aqui.
![]()
Viva a emoção de voar alto no jogo de crash Aviatrix Brasil, onde cada rodada pode trazer grandes vitórias e pura adrenalina!
![]()
Double Fortune oferece o dobro de emoção e romance — perfeito para quem quer uma experiência inesquecível.
![]()
No mundo dos cowboys e duelos, Wild West Duels transforma cada rodada em uma nova aventura premiada.
![]()
Sugar Rush é uma explosão doce de cores e prêmios — doces que encantam e pagam!
Definição de Aprendizado de Máquina Supervisionado
O aprendizado supervisionado é um tipo de aprendizado de máquina em que os dados inseridos no modelo são "marcados". Uma marca simplesmente significa que o resultado da observação (ou seja, a série de dados) é conhecido. Por exemplo, se seu modelo estiver tentando prever se seus amigos irão jogar golfe ou não, você pode ter variáveis como clima, dia da semana e assim por diante. Se seus dados estiverem rotulados, então sua variável terá o valor 1 se seus amigos forem jogar golfe e o valor 0 se eles não forem.
Definição de Aprendizado de Máquina Não Supervisionado
Como você pode imaginar, quando se trata de dados rotulados, o aprendizado não supervisionado é o oposto do aprendizado supervisionado. No aprendizado não supervisionado, você não pode saber se seus amigos estão jogando golfe ou não - apenas o computador pode encontrar padrões usando o modelo para adivinhar o que já aconteceu ou prever o que acontecerá.
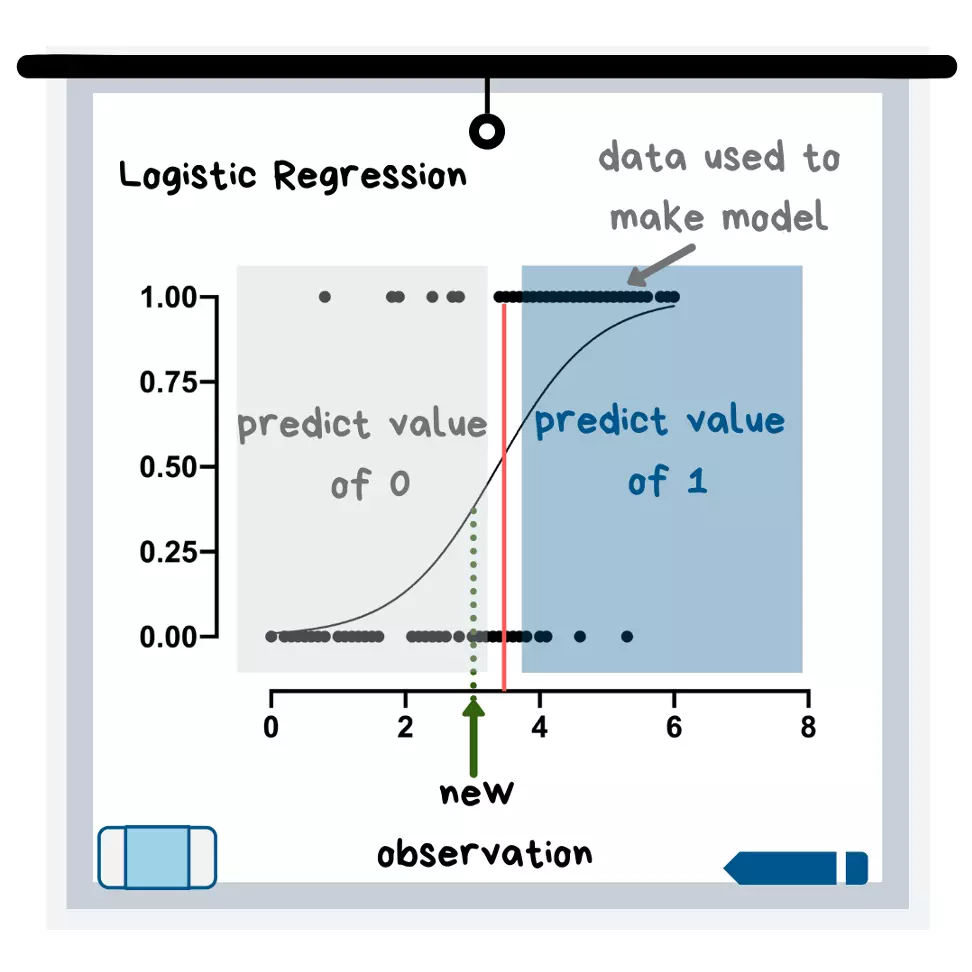
Regressão Logística
A regressão logística é usada para resolver um problema de classificação. Isso significa que sua variável de destino (aquela que você deseja prever) é composta por categorias. Essas categorias podem ser sim/não, ou algo como um número de 1 a 10 que representa a satisfação do cliente. Um modelo de regressão logística usa uma equação para criar uma curva em seus dados e então usa essa curva para prever os resultados de uma nova observação.
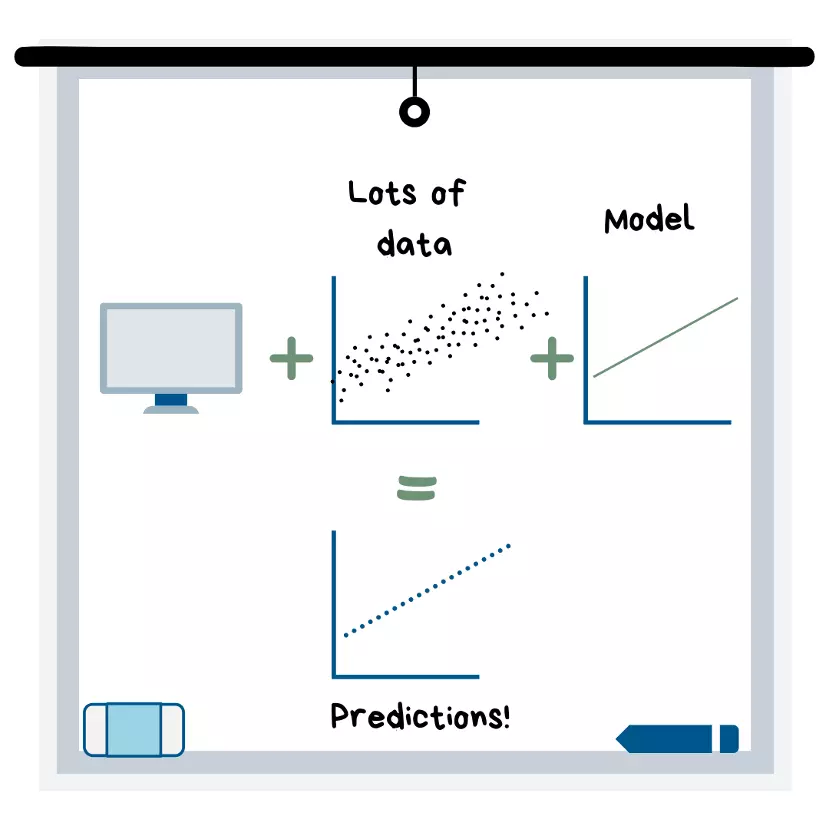
Ilustração da Regressão Logística
No gráfico acima, a nova observação teria uma previsão de 0 porque está no lado esquerdo da curva. Se você olhar para os dados dos quais a curva é desenhada, isso faz sentido porque na área de "valor previsto 0" do gráfico, a maioria dos pontos no eixo y tem o valor 0.
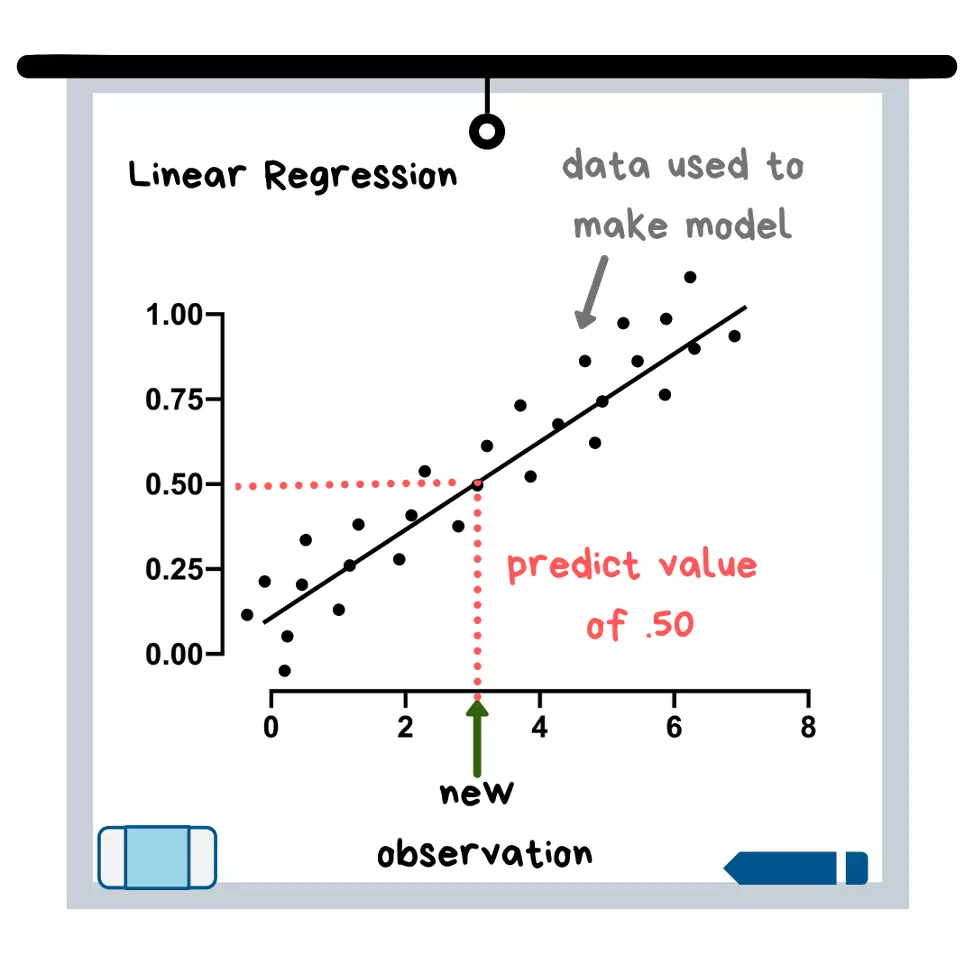
Regressão Linear
Muitas vezes, a regressão linear se torna o primeiro modelo de aprendizado de máquina que as pessoas aprendem. Isso se deve ao fato de que seu algoritmo (em outras palavras, uma equação) é bastante simples de entender usando apenas uma variável x - você simplesmente desenha a linha mais adequada - um conceito que é ensinado na escola primária. A linha de melhor ajuste é então usada para prever novos pontos de dados (veja a ilustração).
Ilustração da Regressão Linear
A regressão linear é um pouco semelhante à regressão logística, mas é usada quando a variável de destino é contínua, o que significa que pode assumir quase qualquer valor numérico. Na verdade, qualquer modelo com uma variável de destino contínua pode ser classificado como uma "regressão". Um exemplo de variável contínua seria o preço de venda de uma casa.
A regressão linear é bem interpretada. A equação do modelo contém coeficientes para cada variável, e esses coeficientes mostram quanto a variável de destino muda com a menor mudança na variável independente (variável x). Se você mostrar isso com os preços de venda de uma casa como exemplo, isso significa que você poderia olhar para a equação de regressão e dizer algo como "ah, isso me diz que para cada metro quadrado adicional do tamanho da casa (variável x), o preço de venda (variável de destino) é aumentado em $25."
Vizinhos mais Próximos (KNN)
Este modelo pode ser usado para classificação ou para regressão. O nome - "Aos Vizinhos Mais Próximos" não deve confundi-lo. Para começar, o modelo exibe todos os dados em um gráfico. A parte "K" do nome refere-se ao número de pontos de dados vizinhos mais próximos que o modelo observa para determinar qual deve ser o valor previsto (veja a ilustração abaixo). Como futuro cientista de dados, você escolhe um valor K e pode experimentá-lo para ver qual valor faz as melhores previsões.
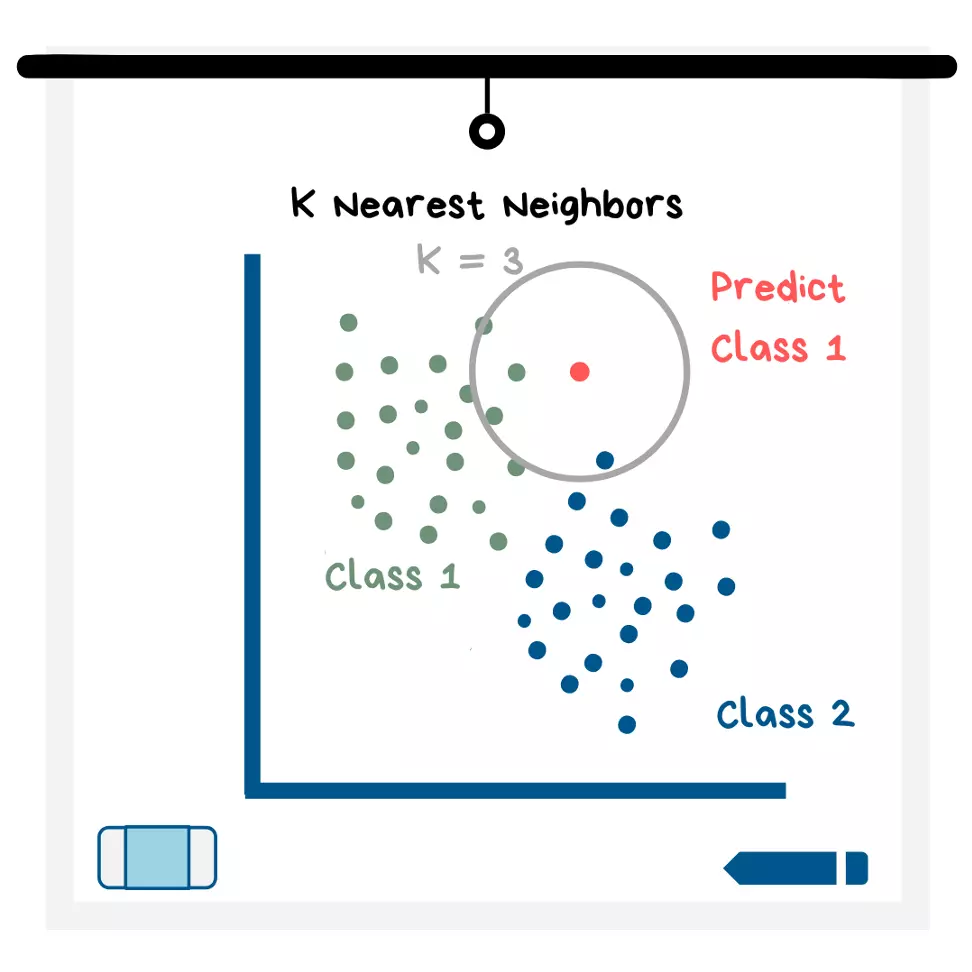
Ilustração de Vizinhos mais Próximos
Todos os pontos de dados no círculo K=__ recebem um "voto" sobre qual deve ser o valor da variável de destino para este novo ponto de dados. O valor que recebe mais votos é o valor que o KNN prevê para o novo ponto de dados. Na ilustração acima, 2 vizinhos mais próximos são da classe 1 enquanto 1 vizinho é da classe 2. Portanto, o modelo previria a classe 1 para este ponto de dados. Se o modelo prever um valor numérico e não uma categoria, então todos os "votos" são valores numéricos, que são médios para obter a previsão.
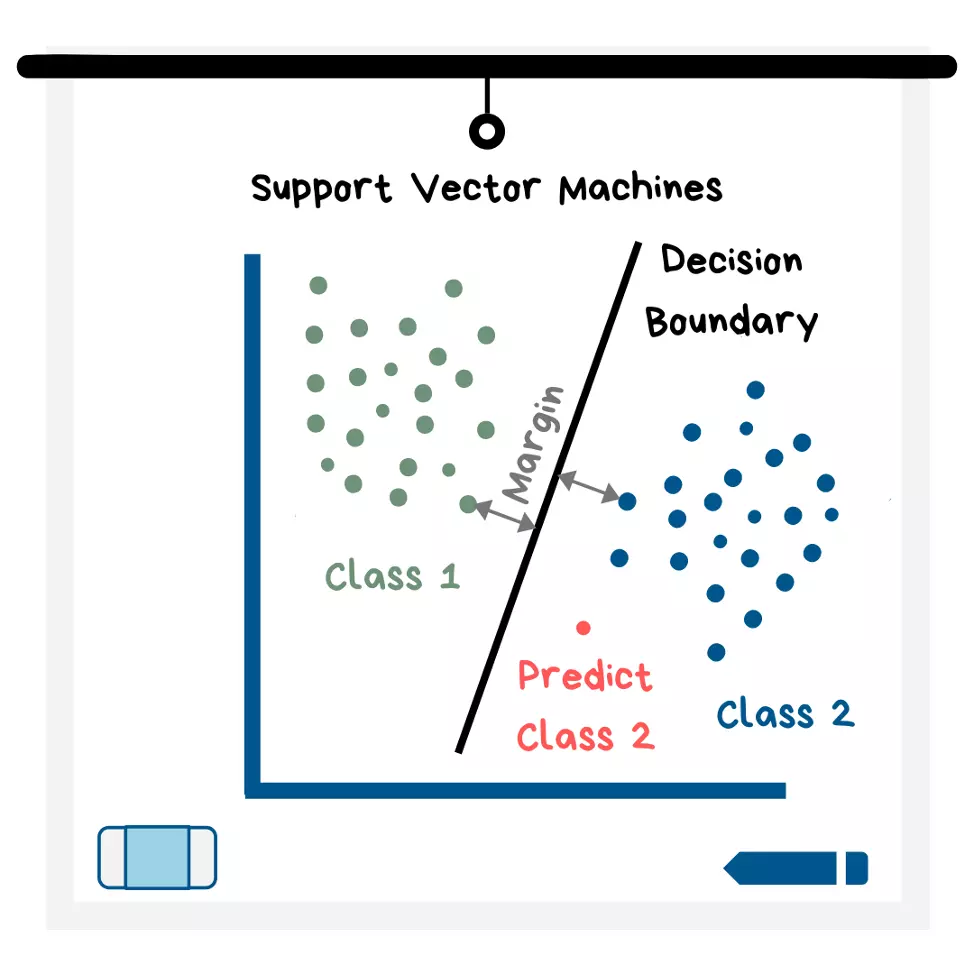
Máquinas de Vetores de Suporte (SVMs)
A maneira como os vetores de suporte funcionam é que eles estabelecem limites entre os pontos de dados onde a maioria de uma classe cai de um lado do limite (por exemplo, em 2D seria uma linha) e a maioria da outra classe cai do outro lado do limite.
Ilustração das Máquinas de Vetores de Suporte
A maneira como funciona também é que a máquina procura encontrar o limite com o maior limite. O limite é determinado pela distância entre o limite e os pontos mais próximos de cada classe (veja a ilustração). Novos pontos de dados são então construídos e colocados em uma classe específica, dependendo de qual lado do limite eles caem.
Eu explico este modelo com um exemplo de classificação, mas você também pode usá-lo para regressão!
Árvores de Decisão e Florestas Aleatórias
Já falei sobre isso em um artigo anterior, você pode encontrá-lo aqui (Árvores de Decisão e Florestas Aleatórias perto do final):
Agora estamos prontos para passar para o aprendizado de máquina não supervisionado. Deixe-me lembrar que isso significa que nosso conjunto de dados não está rotulado, então não sabemos os resultados de nossas observações.
Agrupamento K Means
Quando você usa o agrupamento K, você deve começar assumindo que existem K grupos em seu conjunto de dados. Como você não sabe quantos grupos seus dados realmente têm, você deve experimentar diferentes valores de K e usar visualização e métricas para descobrir qual valor de K é apropriado. O método K significa funciona melhor com grupos circulares do mesmo tamanho.
Este algoritmo primeiro seleciona os melhores K pontos de dados para formar o centro de cada grupo K. Em seguida, repete as seguintes 2 etapas para cada ponto:
1. Atribui um ponto de dados ao centro de grupo mais próximo
2. Cria um novo centro, tirando a média de todos os pontos de dados deste grupo
Agrupamento DBSCAN
O modelo de agrupamento DBSCAN difere do método K significa no sentido de que você não precisa inserir um valor K, e ele pode encontrar grupos de qualquer forma (veja a ilustração abaixo). Em vez de especificar o número de grupos, você insere o número mínimo de pontos de dados que deseja que estejam presentes no grupo e o raio ao redor do ponto de dados para encontrar o grupo. O DBSCAN encontrará os grupos para você! Além disso, você pode alterar os valores usados para criar o modelo até obter grupos adequados para seu conjunto de dados.
Além disso, o modelo DBSCAN classifica pontos de "ruído" (ou seja, pontos que estão longe de todas as outras observações) para você. Este modelo funciona melhor do que o método K significa quando os pontos de dados estão muito próximos uns dos outros.
Redes Neurais
Na minha opinião, as redes neurais são os modelos mais legais e misteriosos. Elas são chamadas de redes neurais porque são modeladas após os neurônios do nosso cérebro. Esses modelos trabalham para encontrar padrões em um conjunto de dados, às vezes encontram padrões que um humano nunca poderia encontrar.
As redes neurais trabalham com dados mais complexos, como imagens ou áudio. Elas estão por trás de muitos dos recursos de software que vemos o tempo todo nos dias de hoje, desde o reconhecimento facial até a classificação de texto. As redes neurais podem ser usadas quando os dados são rotulados (ou seja, aprendizado supervisionado) e também quando os dados não são rotulados (aprendizado não supervisionado).
Conclusão
Espero que este artigo não apenas aumente sua compreensão dos modelos acima, mas também o ajude a entender o quão legais e úteis eles são! Quando deixamos o computador fazer o trabalho/aprender, podemos relaxar e observar que padrões ele encontra. Às vezes, pode ser tudo confuso, porque até mesmo especialistas não entendem a lógica exata pela qual um computador chega a uma determinada conclusão, mas em alguns casos, tudo o que nos importa é a qualidade da previsão!
No entanto, há casos em que nos importamos com como o computador chegou a uma previsão, como quando usamos um modelo para determinar quais candidatos a emprego são dignos da primeira rodada de entrevistas. Se você quiser saber mais sobre isso, aqui está uma palestra TED que você pode assistir e apreciar mesmo que você não seja um cientista de dados. Versão em inglês.